Data Deep Dive
It starts with a question. How many? Which one? Is this weird?
Your data can often contain the answer, but data can be fickle.
A Data Deep Dive is a data science project that takes an idea or hypothesis, and turns it into confidence, validation, or a new direction entirely.
What is a Data Deep Dive?
Put simply, a Data Deep Dive is a data science project designed to answer the question: “is your data ready to solve this problem?” It could be testing a set of algorithms, creating a set of visualisations, or building the first iteration of a machine learning model.

At Razor we thrive on the creative freedom to solve problems, but we recognise that a data solution is no use if it doesn’t stand up to scientific rigour. A Data Deep Dive uses a robust data science process to get to the answer quickly, but backed up with science.
The outcome is the confidence and evidence to back up a data science approach to solving a problem. The next step depends on what we find. Whether it’s productionising a validated machine learning model, or implementing a new dataset into your database, a Data Deep Dive gives us clarity with minimum investment.
Why should I do a Data Deep Dive?
Data can be a powerful tool when applied correctly, but without the rigour to back it up, it risks leading you down the wrong path.
You need to understand what the right path is quickly. The Data Deep Dive has been developed to ensure a project is worth pursuing before taking it to the next level.
To keep things manageable, Data Deep Dives focus on a small bite sized chunk of your data estate. By focusing on a small piece at a time, we avoid getting bogged down and help get you started.
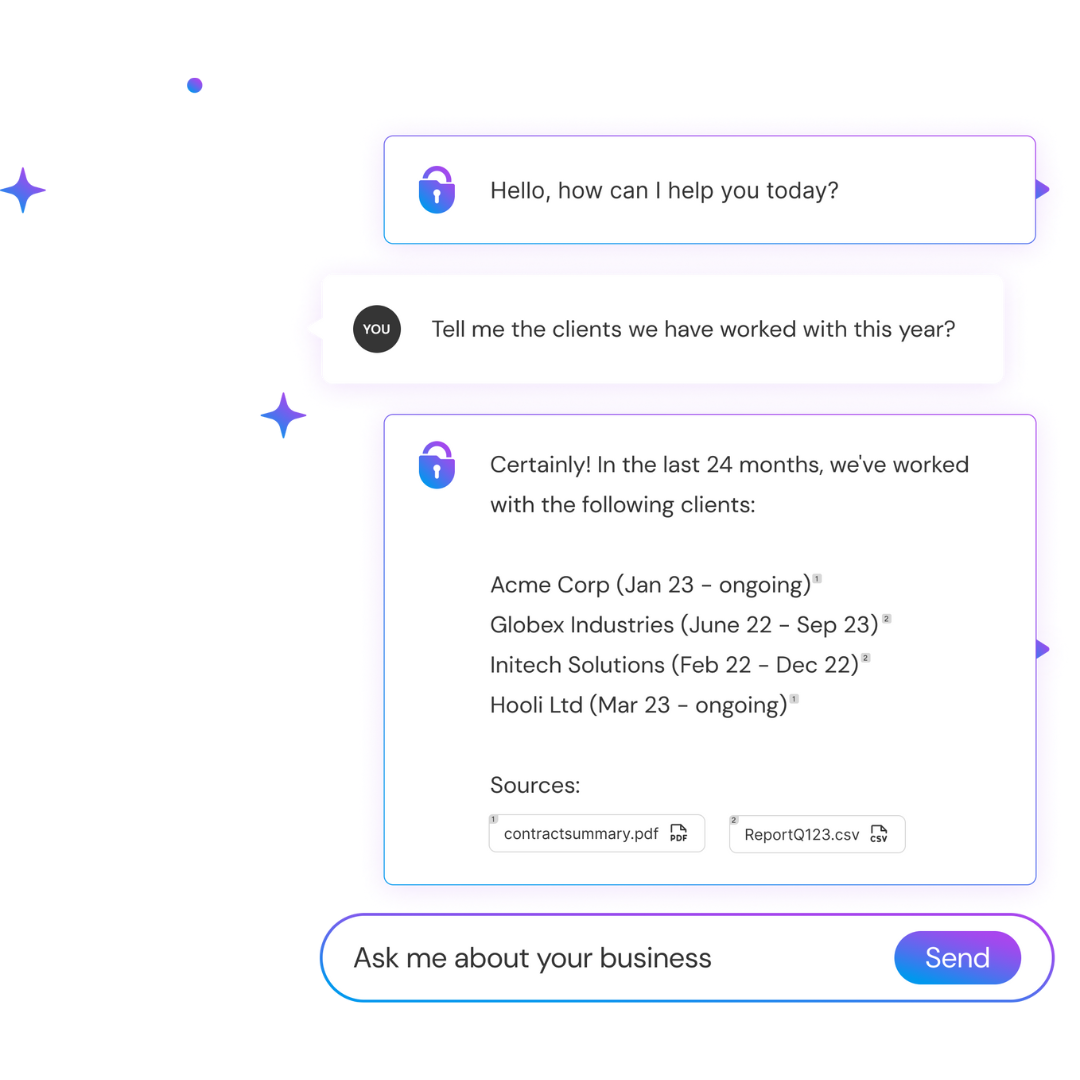
Unlock the power of your AI
Where to start with AI
Sometimes it can be hard to know where to start and this is amplified with AI. It's complicated, right?
What tools can we use? What processes can we automate? Can AI really do that? What happens with my data and IP?
We have you covered with our AI Assessments. We are your sherpas and we can guide you through the complexities so that you have the clarity and confidence to make the right move with AI.
How to dive into your data
We build on a robust data science process to structure our approach to answering hypotheses and, if required, building models.

We look to prove or disprove our hypotheses quickly so we know whether to proceed or change direction with minimum cost.
Our in-house expertise of developing software helps us embed models we build so that people can use them.
Start your Data journey

